
DataformのREST APIを用いてDataformのGitリポジトリのファイルを複製するスクリプト
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
概要
DataformはサードパーティのGit(GitHubやGitLabなど)を利用することができ、多くの場合こちらを利用することが多いと思います。が、社内規則など諸般の事情でDataformに元々あるGit(以下内蔵Git)を利用しないといけないケースもあるかもしれません。またはサードパーティのリポジトリを利用していない場合など。
そういった時に役立つのが内蔵Gitですが、サードパーティのGitと比べるとどうしても使い勝手が寂しいところがあります。
その内蔵Gitから、ファイルを全てローカルにダウンロードしたいということがありましてなんとかならんものかと試行錯誤して思い立ったのがDataformのREST APIを用いてスクリプトを作成してそれでファイルをゲットするという方法でした(ファイル全てをダウンロードする方法は画面上では、存在しないはず)。
今回の記事では、実際に作成したスクリプトをもとにどうやって内蔵Gitからデータを取得するのかを解説しています。
※今回作成しているスクリプトはCloudShellで動作させる前提で作成しています(メタデータサーバから認証トークンを取得するようにしているため)。Cloud Shellでもファイル出力できればCloud Shellからローカルにダウンロードすることができるため。
この記事の対象者
- Dataformの内蔵Gitからデータを取得したい人(サードパーティのGit(GitHubやGitLabなど)は対象外)
早速本編
まずはサンプルコードです
import os
import requests
import json
import base64
# 定数の定義
ENDPOINT = "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token"
PROJECT_ID = "PROJECT ID" #プロジェクトID
LOCATION = "asia-northeast1" #Dataformのリポジトリがあるリージョン
REPOSITORY = "リポジトリ名" #Dataformのリポジトリ名
BASE_PATH = "./cloned_repository" # ローカルに作成するディレクトリのルート
def fetch_token():
'''
Token取得用関数
指定されたエンドポイントからアクセストークンを取得します。
'''
token_header = {"Metadata-Flavor": "Google"}
token_response = requests.get(ENDPOINT, headers=token_header)
token_response.raise_for_status()
token_json_data = token_response.json()
token = token_json_data["access_token"]
return token
def query_directory_contents(project_id, location, repository, directory=""):
'''
ディレクトリ内容クエリ関数
指定されたリポジトリ内のディレクトリ内容をクエリして一覧を取得します
'''
url = f"https://dataform.googleapis.com/v1beta1/projects/{project_id}/locations/{location}/repositories/{repository}:queryDirectoryContents"
headers = {
"Authorization": f"Bearer {fetch_token()}"
}
params = {
"path": directory
}
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
def read_file(project_id, location, repository, file_path):
'''
ファイル読み取り関数
指定されたファイルの内容を取得します
'''
url = f"https://dataform.googleapis.com/v1beta1/projects/{project_id}/locations/{location}/repositories/{repository}:readFile"
headers = {
"Authorization": f"Bearer {fetch_token()}"
}
params = {
"path": file_path
}
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json().get("contents", "")
def recursive_search(project_id, location, repository, directory=""):
'''
再帰的検索関数
指定されたディレクトリ内のすべてのファイルとディレクトリを再帰的に検索します
'''
contents = query_directory_contents(project_id, location, repository, directory)
all_entries = []
for entry in contents.get("directoryEntries", []):
if "file" in entry:
all_entries.append(f"{directory}/{entry['file']}" if directory else entry['file'])
elif "directory" in entry:
sub_directory = f"{directory}/{entry['directory']}" if directory else entry['directory']
all_entries.extend(recursive_search(project_id, location, repository, sub_directory))
return all_entries
def create_local_file_structure(base_path, file_path, file_contents):
'''
ローカルファイル構造作成関数
指定されたパスにファイルを作成し、その内容を書き込みます
'''
full_path = os.path.join(base_path, file_path)
os.makedirs(os.path.dirname(full_path), exist_ok=True)
with open(full_path, 'wb') as file:
file.write(base64.b64decode(file_contents))
def main():
'''
メイン関数
プロジェクトID、ロケーション、およびリポジトリ名を指定して、リポジトリ内のすべてのファイルをローカルに作成します
'''
all_entries = recursive_search(PROJECT_ID, LOCATION, REPOSITORY)
for entry in all_entries:
print(f"Processing file: {entry}")
file_contents = read_file(PROJECT_ID, LOCATION, REPOSITORY, entry)
if not file_contents:
print(f"Warning: File contents are empty for {entry}")
create_local_file_structure(BASE_PATH, entry, file_contents)
print(f"Created file: {os.path.join(BASE_PATH, entry)}")
if __name__ == "__main__":
main()
上記が今回作成したスクリプトです。
処理の流れ、個別の処理について解説していきます。
処理フロー
処理フローは以下のイメージとなります
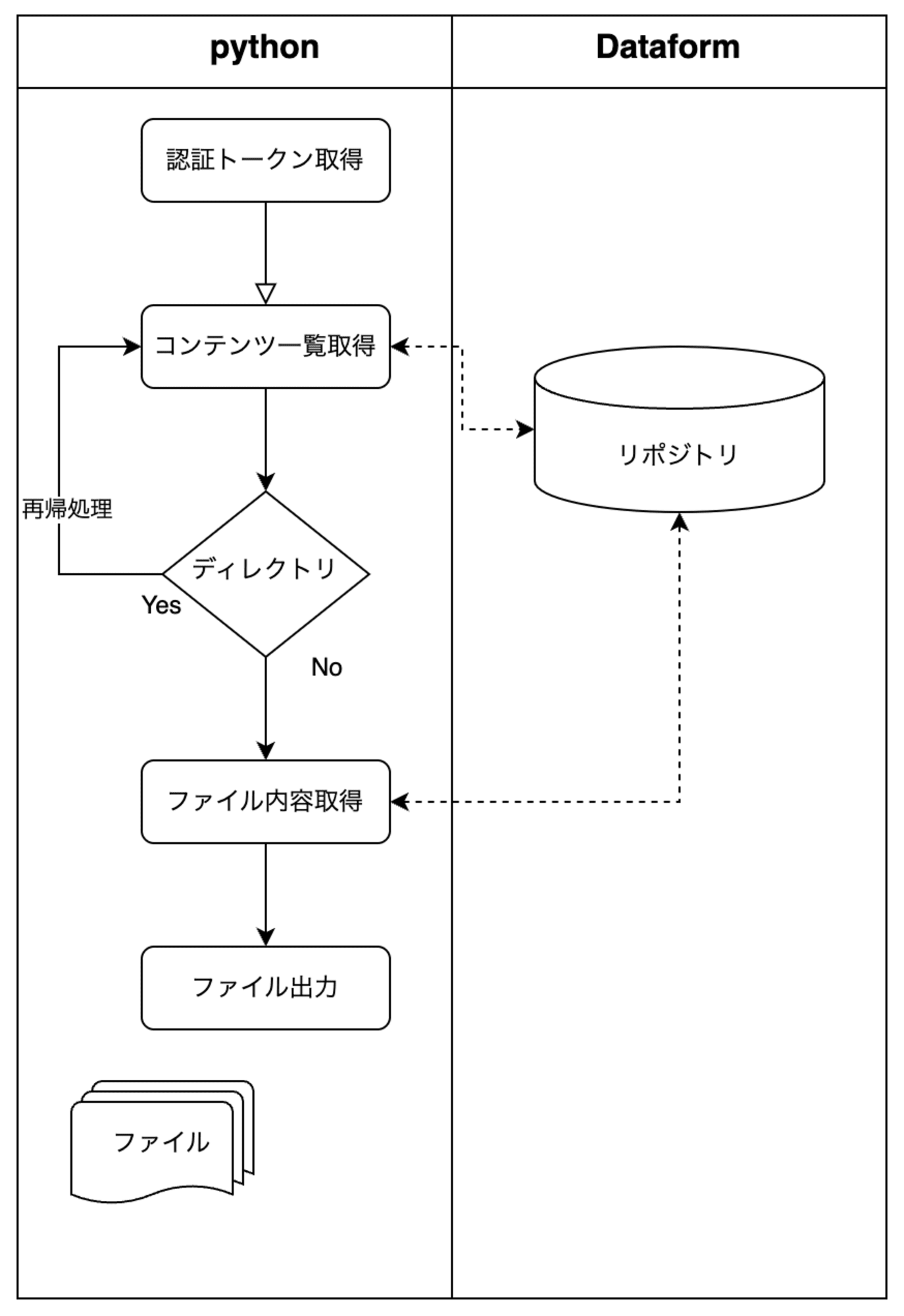
- トークンの取得
fetch_token関数を呼び出し、 メタデータサーバからアクセストークンを取得します。 - ディレクトリ内容のクエリ
recursive_search関数が最初に呼び出され、query_directory_contents関数を使用して指定されたリポジトリ内のディレクトリ内容をクエリします。 - ディレクトリとファイルの再帰的検索
recursive_search関数が再帰的に呼び出され、すべてのサブディレクトリとファイルを探索します。
各ディレクトリ内のエントリがリストに追加されます。 - ファイル内容の読み取り
main関数で、取得したすべてのファイルエントリに対してread_file関数を呼び出し、ファイルの内容を取得します。 - ファイル内容のデコード
read_file関数で取得したBase64エンコードされたファイル内容をデコードします。 - ローカルファイルの作成
create_local_file_structure関数を使用して、デコードされたファイル内容をローカルの指定されたディレクトリ構造に従ってファイルとして保存します。
使用しているAPIと注意点
ディレクトリ・ファイル一覧は以下のAPIで取得
ファイル内容取得は以下のAPIを使用しています
注意点
-
queryDirectoryContents・readFileどちらのAPIもともにWorkspace単位でも存在していて、エンドポイントも別となっています。
今回はリポジトリを対象にしたかったのでリポジトリが対象となっているAPIを使用しています -
ファイル内容取得のAPI(readFile)はレスポンスのファイル内容(contents)がBase64でエンコードされているのでデコードしてあげる必要があります。その処理も組み込んであります(5.ファイル内容のデコード)
-
ファイル内容取得のAPI(readFile)はリクエストパラメータに
commitShaを含めることができます。今回はこちらは設定していません。設定を省略した場合HEADのデータが取得されます -
APIの認証ではBearer認証を用いています。認証トークンはメタデータサーバから取得しました。
※メタデータサーバはローカル環境からではアクセスできません。Google Cloud環境上のリソース(Cloud Shell Cloud Functions Comput Engineなど)からアクセスできます
https://cloud.google.com/docs/authentication/rest?hl=ja#metadata-server -
ページネーションは設定していないのでリポジトリ内のファイルが多すぎる場合はページネーションを追加で実装する必要があります
設定
| 変数名 | 説明 |
|---|---|
| ENDPOINT | メタデータサーバのURLのため固定値:"http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token" |
| PROJECT_ID | プロジェクトID |
| LOCATION | Dataformのリポジトリがあるリージョン |
| REPOSITORY | Dataformのリポジトリ名 |
| BASE_PATH | 指定したパスにディレクトリ・ファイルが作成される |
実行する
適当な名前をつけて、pythonコマンドで叩きます。
叩くと、少し待つと順番にファイル名がどんどん出力されていきファイルが指定したところに作成されます。
~$ python get_dataform_code.py
Processing file: .gitignore
Created file: ./cloned_repository/.gitignore
Processing file: dataform.json
Created file: ./cloned_repository/dataform.json
・・・以下省略
まとめ
内蔵Gitの機能が強化されたらこの記事は嬉しいことに無用のものになります笑。
とはいえ現時点では自分はとっても助かったスクリプトです。他にももっといいやり方があるかもなのでもっともっといろんなAPIを試してみようと思っています。
この記事が、Dataform の内蔵Gitからファイルを入手したいかたのお役に立てば嬉しいです。それではまた。ナマステー
参考










